k-折交叉驗證
k-折交叉驗證(K-fold cross-validation)是交叉驗證方法里一種。它是指將樣本集分為k份,其中k-1份作為訓練數據集,而另外的1份作為驗證數據集。用驗證集來驗證所得分類器或者模型的錯誤率。一般需要循環k次,直到所有k份數據全部被選擇一遍為止。
有關交叉驗證的介紹可參考作者另一博文:
http://blog.csdn.net/yawei_liu1688/article/details/79138202
R語言實現
K折交叉驗證,隨機分組
數據打折-數據分組自編譯函數:進行交叉檢驗首先要對數據分組,數據分組要符合隨機且平均的原則
library(plyr)
CVgroup <- function(k,datasize,seed){
cvlist <- list()
set.seed(seed)
n <- rep(1:k,ceiling(datasize/k))[1:datasize] #將數據分成K份,并生成的完成數據集n
temp <- sample(n,datasize) #把n打亂
x <- 1:k
dataseq <- 1:datasize
cvlist <- lapply(x,function(x) dataseq[temp==x]) #dataseq中隨機生成k個隨機有序數據列
return(cvlist)
}
k <- 10
datasize <- nrow(iris)
cvlist <- CVgroup(k = k,datasize = datasize,seed = 1206)
cvlist結果輸出示例:

K折交叉驗證
第一種方法:循環語句寫驗證
data <- iris
pred <- data.frame() #存儲預測結果
library(plyr)
library(randomForest)
m <- seq(60,500,by = 20) #如果數據量大盡量間隔大點,間隔過小沒有實際意義
for(j in m){ #j指的是隨機森林的數量
progress.bar <- create_progress_bar("text") #plyr包中的create_progress_bar函數創建一個進度條,
progress.bar$init(k) #設置上面的任務數,幾折就是幾個任務
for (i in 1:k){
train <- data[-cvlist[[i]],] #剛才通過cvgroup生成的函數
test <- data[cvlist[[i]],]
model <-randomForest(Sepal.Length~.,data = train,ntree = j) #建模,ntree=j 指的樹數
prediction <- predict(model,subset(test,select = -Sepal.Length)) #預測
randomtree <- rep(j,length(prediction)) #隨機森林樹的數量
kcross <- rep(i,length(prediction)) #i是第幾次循環交叉,共K次
temp <- data.frame(cbind(subset(test,select = Sepal.Length),prediction,randomtree,kcross))#真實值、預測值、隨機森林樹數、預測組編號捆綁在一起組成新的數據框tenp
pred <- rbind(pred,temp) #temp按行和pred合并
print(paste("隨機森林:",j)) #循環至樹數j的隨機森林模型
progress.bar$step() #輸出進度條。告知完成了這個任務的百分之幾
}
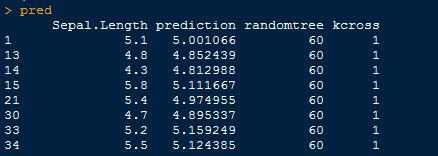
}結果輸出示例1:

結果輸出示例2:指標分別為真實值、預測值、隨機森林樹數、預測組編號
第二種方法:apply家族lapply
當測試的循環數較多或單任務耗時較多時,apply家族優勢特別明顯
data <- iris
library(plyr)
library(randomForest)
k = 10
j <- seq(10,10000,by = 20) #j樹的數量
i <- 1:k #K折
i <- rep(i,times = length(j))
j <- rep(j,each = k) #多少折,each多少
x <- cbind(i,j)
cvtest <- function(i,j){
train <- data[-cvlist[[i]],]
test <- data[cvlist[[i]],]
model <- randomForest(Sepal.Length~.,data = train,ntree = j)
prediction <- predict(model,subset(test,select = -Sepal.Length))
temp <- data.frame(cbind(subset(test,select = Sepal.Length),prediction))
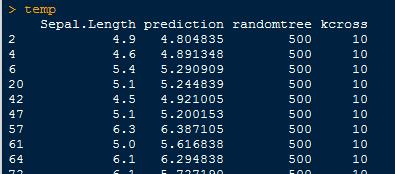
}結果輸出示例3:指標分別為真實值、預測值、隨機森林樹數、預測組編號
system.time(pred <- mdply(x,cvtest)) 
mdyly在plyr包中:輸出三個指標:“用戶”“系統”“流逝”。其中“流逝”應該是這段代碼從開始到結束的真正時間。對于一般單線程的程序來說這個時間近似于用戶時間和系統時間之和,可以看出共運行了1386秒。
到此這篇關于R語言交叉驗證的文章就介紹到這了,更多相關R語言交叉驗證的實現代碼內容請搜索html5模板網以前的文章希望大家以后多多支持html5模板網!
【網站聲明】本站部分內容來源于互聯網,旨在幫助大家更快的解決問題,如果有圖片或者內容侵犯了您的權益,請聯系我們刪除處理,感謝您的支持!